Web OCR
Optical Character Recognition(OCR)
この手のものはたくさんありますが、
ここではtesseract-ocrを認識エンジンとして使ってみます。
tesseract-ocrはオープンソースの中では、比較的認識率の高いエンジンです。
日本語等は使えません、アルファベットのみ対応しています。
もともとHPのコードでしたが、HPがOCR事業から撤退したため長らく「お蔵入り」
していたのをGoogleが引き継いで、オープンソースとして公開しています。
古いコードをベースにしているので、少々古典的なアルゴリズムを使っているかも。
(別途でOpenCVのようなComputerVisionをつかったOCRも試してみます。-- basicOCR)
tesseract-ocr
ご注意
WebOCRをご使用いただきありがとうございます。
昨今、使用状況を確認してみますと、かなりハードな要求が多いと思われます。
市販の認識エンジンとは比較になりませんのでご注意ください。
tesseract-ocrは素のままで実行しています(トレーニングデータはまだ作ってません)。
以下にサンプルを用意しました。この程度と認識された上でご使用ください。
サンプル
Web OCR
Web OCRのトレーニングについて
basicOCR
付録
トップページ| サイトマップ|
Web OCR
●tesseract-ocrを使った文字認識
Web OCR
初期画面はこんな感じ。
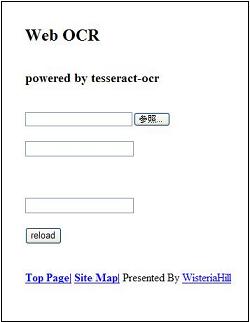
参照する文字画像はJPEG形式です。
例えばこんな画像。
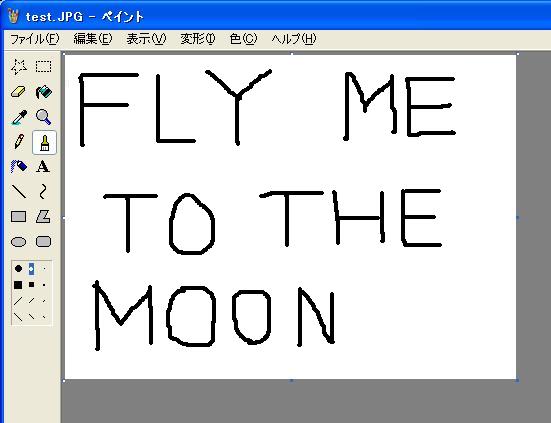
参照が完了すると、即認識を開始します。
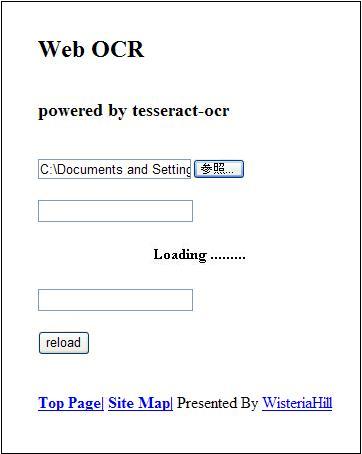
結果はこんな感じ。
上のフィールドに認識結果、
下のフィールドに翻訳結果が入ります。
翻訳は、GoogleのAjax Language APIを使っています。

TOP
Web OCRのトレーニングについて
認識率向上には、tesseract-ocr用にトレーニングデータをつくる必要があります。
このページを参照
to be continued.
TOP
サンプル
4つのサンプルを用意しました。下の画像をダウンロードして、お使いください。
使用上のご注意にもなっています。
サンプル 1

サンプル 2

サンプル 3

上の画像からノイズを省いたもの
サンプル 4

TOP
basicOCR
検索エンジンから、オリジナルサイトを見つけにくくなってますね。
C++のソースは以下からダウンロードできます。
basicOCR
TOP
付録
スポンサー リンク
スポンサー リンク
スポンサー リンク